Nothing Found
Sorry, no posts matched your criteria
MEDIA ANALYTICS
PROJECTS
PEOPLE
PUBLICATIONS
PATENTS
We propose an approach for injecting prior domain structure into CNN training by supervising hidden layers with intermediate concepts. We formulate a probabilistic framework that predicts improved generalization through our deep supervision. This allows training only from synthetic CAD renderings where concept values can be extracted, while achieving generalization to real images. We obtain state-of-the-art performances on 2D and 3D keypoint localization, instance segmentation and image classification, outperforming alternative forms of supervision such as multi-task training.
Collaborators: Chi Li, M. Zeeshan Zia, Quoc-Huy Tran, Gregory D. Hager, Manmohan Chandraker


Deep Supervision with Shape Concepts for Occlusion-Aware 3D Object Parsing
Chi Li, M. Zeeshan Zia, Quoc-Huy Tran, Xiang Yu, Gregory D. Hager, Manmohan Chandraker
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
[PDF] [Supp] [Bibtex]
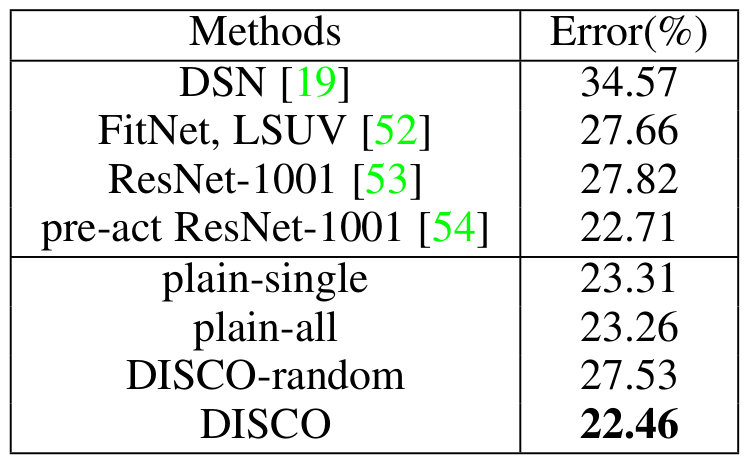
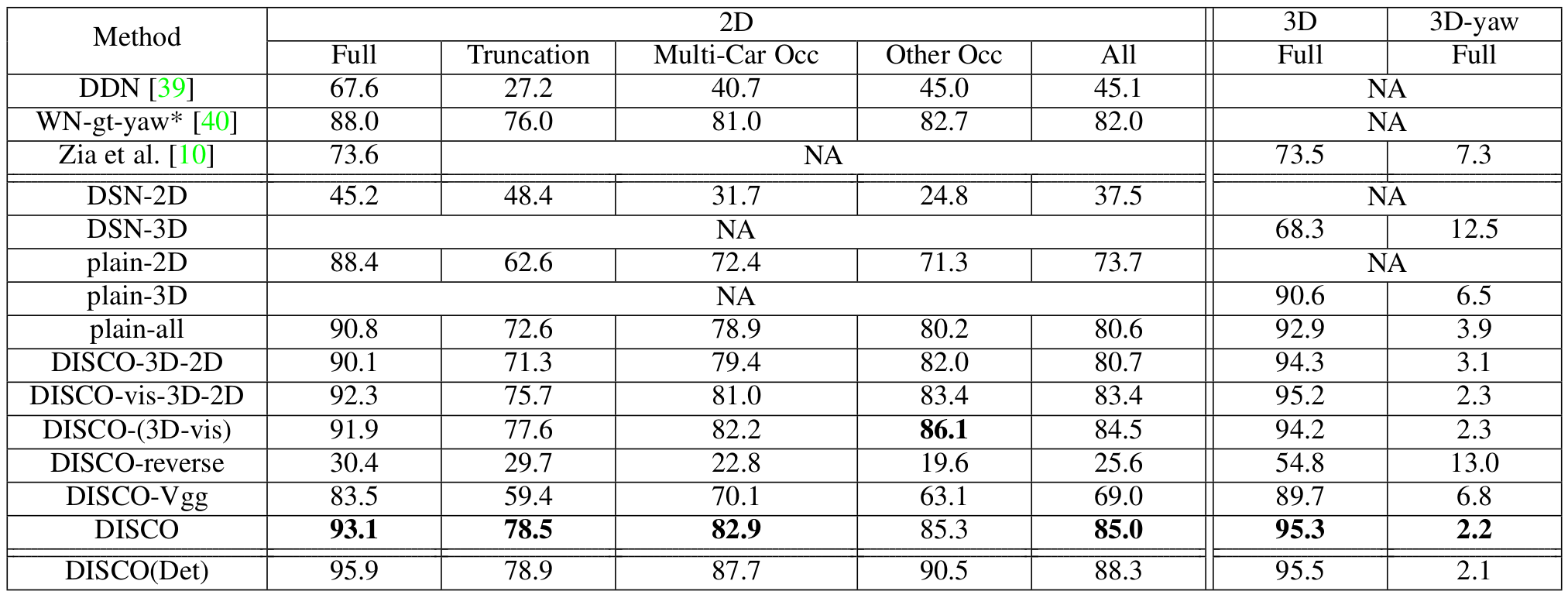
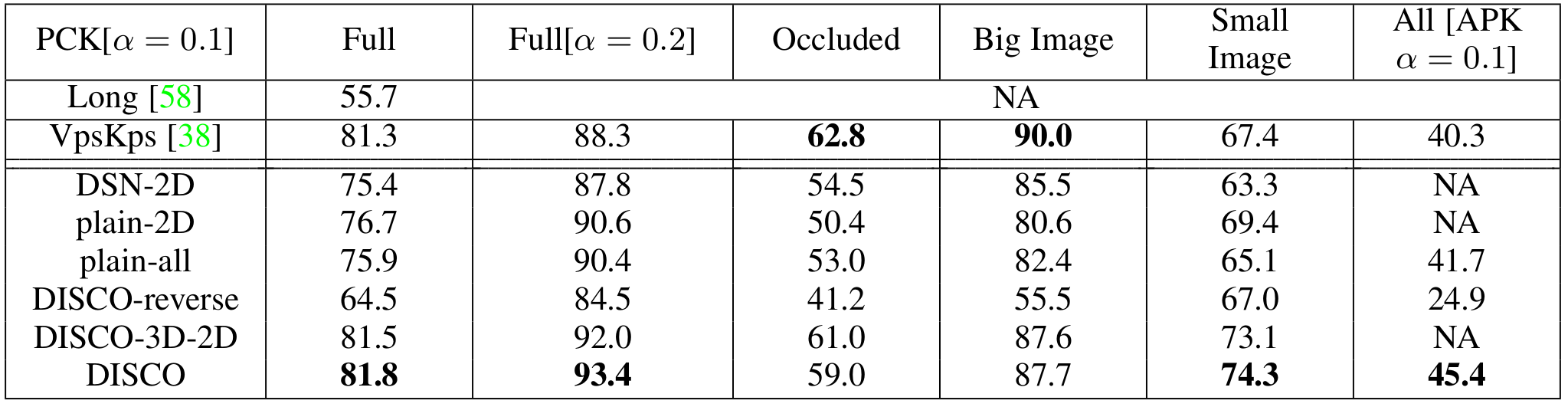
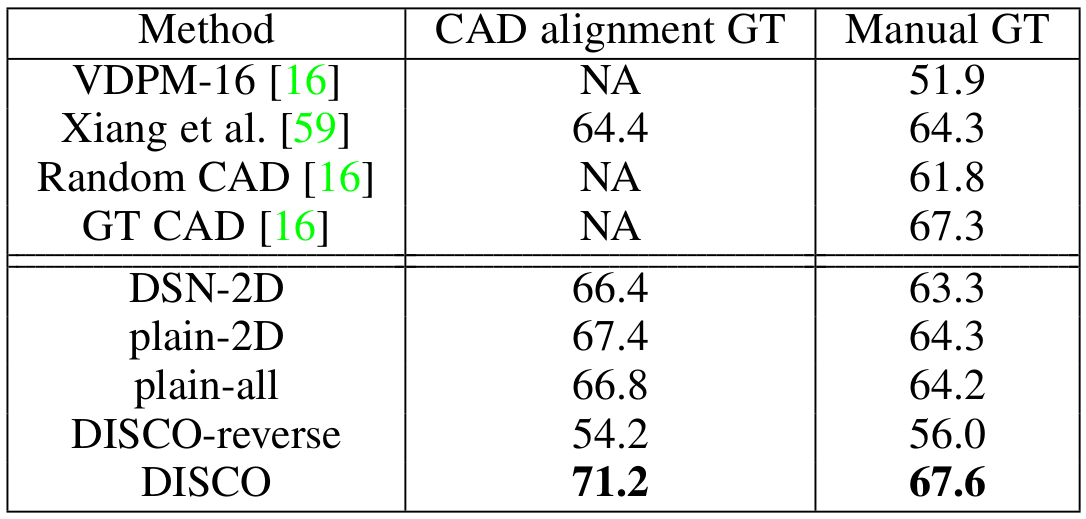
Recent data-driven approaches to scene interpretation predominantly pose inference as an end-to-end black-box mapping, commonly performed by a Convolutional Neural Network (CNN). However, decades of work on perceptual organization in both human and machine vision suggest that there are often intermediate representations that are intrinsic to an inference task, and which provide essential structure to improve generalization. In this work, we explore an approach for injecting prior domain structure into neural network training by supervising hidden layers of a CNN with intermediate concepts that normally are not observed in practice. We formulate a probabilistic framework which formalizes these notions and predicts improved generalization via this deep supervision method. One advantage of this approach is that we are able to train only from synthetic CAD renderings of cluttered scenes, where concept values can be extracted, but apply the results to real images. Our implementation achieves the state-of-the-art performance of 2D/3D keypoint localization and image classification on real image benchmarks including KITTI, PASCALVOC, PASCAL3D+, IKEA, and CIFAR100.We provide additional evidence that our approach outperforms alternative forms of supervision, such as multi-task networks.



Sorry, no posts matched your criteria