Link to: Media Analytics
MEDIA ANALYTICS
PROJECTS
Link to: MA People
PEOPLE
Link to: MA Publications
PUBLICATIONS
Link to: MA Patents
PATENTS
A Parametric Top-View Representation of Complex Road Scenes
We address the problem of inferring the layout of complex road scenes given a single camera as input. We first propose a novel parameterized model of road layouts in a top-view representation, which is not only intuitive for human visualization but also provides an interpretable interface for higher-level decision making. Moreover, the design of our top-view scene model allows for efficient sampling, and thus generation, of large-scale simulated data, which we leverage to train a deep neural network to infer our scene model’s parameters. Finally, we design a conditional random field (CRF) that enforces coherent predictions for a single frame and encourages temporal smoothness among video frames.
Collaborators: Ziyan Wang, Manmohan Chandraker

Project Site
Our goal is to infer the layout of complex driving scenes from a single camera. Given a perspective image (top left) that captures a 3D scene, we predict a rich and interpretable scene description (bottom right), which represents the scene in an occlusion-reasoned semantic top-view. In this paper, we address the problem of inferring the layout of complex road scenes given a single camera as input. To achieve that, we first propose a novel parameterized model of road layouts in a top-view representation, which is not only intuitive for human visualization but also provides an interpretable interface for higher-level decision-making. Moreover, the design of our top-view scene model allows for efficient sampling and, thus, generation of large-scale simulated data, which we leverage to train a deep neural network to infer our scene model’s parameters. Specifically, our proposed training procedure uses supervised domain-adaptation techniques to incorporate both simulated as well as manually annotated data. Finally, we design a Conditional Random Field (CRF) that enforces coherent predictions for a single frame and encourages temporal smoothness among video frames. Experiments on two public data sets show that: (1) Our parametric top-view model is representative enough to describe complex road scenes; (2) The proposed method outperforms baselines trained on manually-annotated or simulated data only, thus getting the best of both; (3) Our CRF is able to generate temporally smoothed while semantically meaningful results.
A Parametric Top-View Representation of Complex Road Scenes Paper
1 Carnegie Mellon University 2 NEC Laboratories America 3 UC San Diego
In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019
Download Paper [CVPR PDF] [arXiv PDF] [NEC Labs America PDF] [Bibtex]
Abstract
In this paper, we address the problem of inferring the layout of complex road scenes given a single camera as input. To achieve that, we first propose a novel parameterized model of road layouts in a top-view representation, which is not only intuitive for human visualization but also provides an interpretable interface for higher-level decision-making. Moreover, the design of our top-view scene model allows for efficient sampling and thus, generation of large-scale simulated data, which we leverage to train a deep neural network to infer our scene model’s parameters. Specifically, our proposed training procedure uses supervised domain adaptation techniques to incorporate both simulated as well as manually annotated data. Finally, we design a Conditional Random Field (CRF) that enforces coherent predictions for a single frame and encourages temporal smoothness among video frames. Experiments on two public data sets show that: (1) Our parametric top-view model is representative enough to describe complex road scenes; (2) The proposed method outperforms baselines trained on manually annotated or simulated data only, thus getting the best of both; (3) Our CRF is able to generate temporally smoothed while semantically meaningful results.

Dataset
Please download our semantic and BEV annotations for KITTI and NuScenes here.
Results
We show a video that displays two qualitative results of our approach on sequential data, demonstrating the impact of the graphical model. This video consists of two short video clips from the KITTI validation set. The descriptions in the video, “Input RGB”, “Prediction” and “wo GM”, are the input RGB image, our final output with temporal CRF and the output without CRF, respectively. The first clip show that our model is able to predict the rotation change smoothly. The second clips demonstrate a more complex example where we approach a four-way intersection and then turn left. By comparing our final prediction to that without CRF, we can clearly see that our proposed CRF model can effectively smooth the predictions.
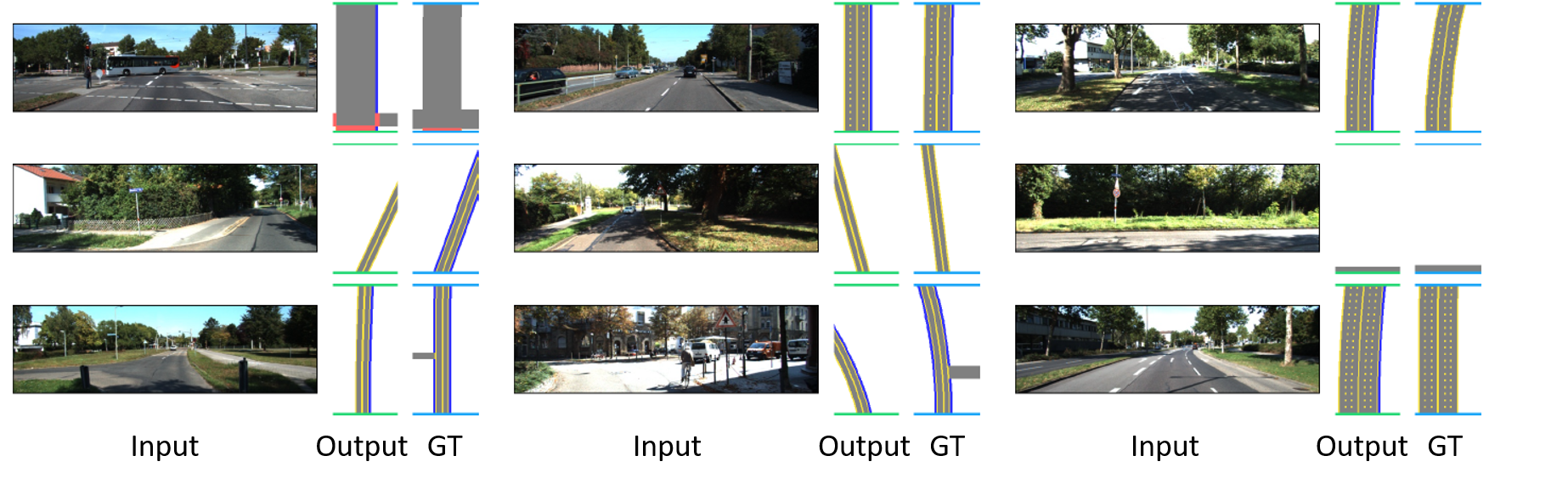
Qualitative results of our method on individual frames from the KITTI dataset. Each example shows perspective RGB, ground truth and predicted semantic top-view, respectively. Our representation is rich enough to cover various road layouts and handles complex scenarios, e.g., rotation, the existence of crosswalks, sidewalks, side-roads and curved roads.
Acknowledgements
We want to thank Kihyuk Sohn for the valuable discussions on domain adaptation and all anonymous reviewers for their comments. This website template is inspired by this project website.